2021. 4. 28. 11:21ㆍ2021/JOB DA STUDY
- 데이터 사이언스 응용 프로그램에서 사용하기 위한 다양한 데이터 소스 설명이 가능하다.
- 데이터에 대한 다양한 라이선스 옵션 비교가 가능하다.
- 데이터 수집을 위한 API의 역할 설명이 가능하다.
- 데이터 정리의 역할을 설명할 수 있다.
- 데이터 수집 기술을 적용해 MongoDB에 데이터 저장 및 관리가 가능하다.
- 여러 출처에서 데이터를 수집하는데 따른 이점 및 문제점을 평가 할 수 있다.
- MongoDB에서 데이터를 추출하기 위한 쿼리 작성이 가능하다.
데이터 사이언스 파이프라인
데이터 수집 -> 데이터 처리 -> 데이터 클리닝 및 통합
- 데이터 및 데이터 수집 소스
- 데이터 전처리와 통합
- 데이터 저장 및 관리(물리적 로컬 시스템 사용에 대한 클라우드 기반 저장 및 처리)
데이터 수집 및 데이터 소스
웹상의 데이터 종류
- 자동차, 보트, 비행기 같은 하드웨어 (자율 주행 자동차의 경우 실시간으로 데이터를 수집하여 처리)
- 디지털 네트워크 (웹 브라우저나 휴대전화에서 매일 보는 웹)
- 인터넷 같은 근본적인 인프라 (패킷 수준의 데이터로 다양한 장치간의 데이터가 통신)
- 정확한 위치에 대한 잠재적 스트림을 실시간으로 생성하는 GPS (핸드폰, 스마트 워치 등에 연결)
정적 데이터 & 스트리밍 데이터
- 정적 데이터 ="DB에서 얻을 수 있는 데이터" (EX - 웹 상의 데이터)
- 스트리밍 데이터 = "실시간으로 처리하는 데이터" (EX - 금융 데이터, GPS 데이터)
웹에서 데이터를 수집할 수 있는 방법 = "RESTful API"
회사는 서버에서 데이터 사용이 가능
RESTful API = 웹이 작동하는 방식의 기초
HTTP = 하이퍼 텍스트 전송 프로토콜 (GET, POST, PUT, DELETE)
URL = 서버의 특정 리소스 식별 - HTTP에 포함된 메소드를 수행
GET: 정상적인 브라우징 (요청)을 하면 데이터는 요청하는 특정 형식(JSON/XML)으로 반환
***API 사용시 주의사항***
1. 모든 회사가 공개적으로 사용가능한 API에서 데이터 사용할 수 있는 것은 아님
-> 인증 및 속도 제한으로 보호되기 때문
-> 라이선스로 인해 상업 용도로 사용할 수 없기 때문
둘의 경우, 비용 지불의 문제가 증가
2. API 변경에 대한 비용 증가 또는 서비스 중단 문제
API 반환 데이터 형식
API에서 얻을 수 있는 데이터 유형으로 XML, JSON 형식이 존재한다.
- JSON
- 자바스크립트의 일부로 데이터를 표현하는 가벼운 수단
- 몽고 DB에서 저장되는 데이터 형식
EX) {"obj_key" : {"good_obj" : true}, "age" = 26, "key" = "value", "gender" = null, "friends" = ["A", "B", "C"]}
API의 대안으로 Python 라이브러리를 사용하는 페이지 웹 스크리핑 기술
- XML
- 일련의 요소 및 속성인 데이터로 데이터를 표현하는데 사용 가능한 형식
- 많은 데이터에 대해 공간을 많이 차지하여 유용하지는 않음
- 일련의 Open tag와 Close tag 사이에 데이터 요소 배치
-HTML
웹페이지의 데이터는 HTML 형식으로 저장된다. (XML 형식과 매우 유사한 형식)
웹 브라우저가 데이터의 의미와 표시 방법을 이해할 수 있는 형식
컴퓨터 프로그램으로 웹페이지를 방문하는 사용자의 프로세스 자동화하여 웹페이지의 모든 데이터 추출이 가능
페이지 스크래핑 from Python
1.
Python Requests Library: 웹 API에서 데이터 수집시 사용할 수 있는 기능 -> HTML
+ Beautiful Soup Library: HTML을 가져와서 통과하게 함
2.
Page Scraping (Scrapy)
더 많은 자동화 기능을 추가하며, 전체 웹 사이트를 직접 크롤링할 수 있는 라이브러리로 기본수준으로 설정하는 것이 매우 간단하다. (목록의 URL을 통해 방문)
***Scrapy의 문제점***
- Scraping 하기전에 항상 웹사이트 루트 안에 파일이 있는지 확인
데이터를 얻으려면 데이터로 수행하려는 작업에 관련하여 지침을 추가해야하는데,
로봇 파일은 로봇이 방문할 수 있는 서버의 페이지와 디렉터리에 대한 일련의 지침을 제공하여 매우 빠르게 수행 가능
예를 들어 구글봇과 같은 봇이 나의 모든 페이지에 방문하기를 원하지만 다른 봇이 나의 대역폭을 차지하는 것은 원치않는 경우도 존재하며, 로봇파일이 없거나, 로봇 파일이 웹사이트 일부에 방문하는 것을 불허하지 않으면 웹사이트 소유자가 봇의 방문을 허가한다고 가정 할 수 있다.
- Page Scraping에는 경고가 표시
로봇 프로토콜에 법적 지위가 없더라도 잠재적인 법적 문제는 존재하므로 참여하기 전에 법률 자문은 필수
데이터 탐구 및 수정
데이터 수집 이후의 전처리 = 작업에 유용한 형식으로 데이터가 준비 되었는지 확인
- 데이터를 추출해 사용가능한 형태로 변환하여, 데이터 조각을 통합할 수 있어야한다.
- 데이터를 평가하여 데이터에서 얻을 수 있는 용도와 가치의 종류를 정확히 파악해 데이터 정제
- 수동적인 데이터 검사는 필수 적이다.
- 데이터 관련 발생 문제
1. 데이터 누락
-> 무시하는 경우, 특정 편향을 유발할 수 있다. 그래서 누락된 부분은 채우는 것이 중요하다.
* 숫자의 경우 데이터가 왜곡될 가능성이 존재
* 주변 데이터를 기반으로 채우기 가능: 양 옆의 평균, Bayesian 방법 ( 확률적으로 가장 가능성이 높은 데이터 값)
2. 데이터에서 이상치 발견
-> 데이터 내에 노이즈 발생 가능성이 존재: by. 데이터 내의 정규 분산
***노이즈가 발생하는 경우***
- 이동평균
데이터의 하위 집합을 수집한 다음 해당 특정 하위 집합의 평균을 구하고 전체 데이터 집합을 통해 이동해 고정된 크기의 하위 집합의 평균을 수집한다.
- 회귀분석
특정 데이터에 가중치를 할당한 다음 로컬에 계산을 수행할 수 있다.
- 클러스터
수동 또는 프로그래밍으로 데이터를 클러스터에 저장 가능하며,
이는 데이터의 의미를 유지하면서 제거 또는 변형 될 수 있는 잠재 이상치의 제거를 돕는다.
3. 일부 데이터 집합만 존재
4. 불필요한 데이터 추가
5. 데이터 내의 다양한 필드간의 불일치 발견
6. API 변경이 발생하여 데이터 표시에 변화 발생
하나 이상의 데이터 소스를 가지는 경우, 단일 데이터 소스에서 얻을 수 없는 추세나 통찰력을 추가적으로 얻을 수 있다.
하지만 이런 경우 두가지를 하나의 일관된 소스로 통합할 수 있어야 한다.
문제점
- 데이터는 다른 곳에서 나올 수 있는데 시간이 지남에 따라 데이터 변경으로 인해 불일치가 발생할 수 있다. --> 데이터의 이름을 다르게 지정하거나, 두가지를 합한 개체명 세트로 통합하기 위해서(고객ID = 사용자 ID)는 많은 시간이 소요된다.
- 통합하는 과정에서 가치와 관련하여 충돌 가능성이 발생한다. -> 어떤 데이터를 사용할 것인지, 어떤 데이터 소스가 가장 신뢰할 만한지 정확하게 결정
개체 해상도 = 다양한 개체를 식별하고 일관된 저장소로 모을 수 있는 프로세스
모든 요소를 다른 모든 요소와 비교하며 검사해야 하므로, 컴퓨터가 자동으로 풀 수 있는 어려운 문제이며, 본질적으로 2차 비용이 필요한 연산이다.
Blocking(블로킹)
개체 해상도에서 개선된 방식으로 개체가 유사한 클러스터 또는 유사한 그룹으로 분할되고, 그런 다음에 개체 해상도가 해당 그룹 내에서 발생하게 된다.
이는 훨씬 더 작은 데이터 집합에서 2차적이기 때문에 계산 비용이 줄어드는 효과가 있다.
- 개체 해상도 단계에서는 필연적으로 데이터 복제가 발생할 수 있다.
개체가 정의 되는 방식인 스키마 레벨, 개체 내의 개별 레코드 또는 필드에서 발생할 수 있다.
- 단어의 동의어 또는 단어의 번역을 확인하는 것
- 번역이나 동의어를 보지 않고 텍스트가 매우 유사한지 확인 가능
- 스키마와 관련된 특정 데이터와 관련 데이터에서 해당 스키마에 대해 많은 추론이 가능
- 복제보다 더 심각한 문제는 복제 데이터가 다양한 답변을 제공하는 경우이다.
데이터 내에서 사용하고자 하는 진정한 답변이 무엇인지 결정해야한다.
* 어떤 데이터가 다른 데이터 보다 신뢰성이 높다고 해서 모두 맞는 것은 아니다.
* 데이터는 시간이 지남에 따라 다양한 방식으로 꾸준히 변화한다.
* 서로 다른 데이터 소스간의 의존성 여부가 발생
(이전 데이터의 결함이 의존된 데이터로 전달 / 업데이터가 안된다면 데이터 무결성이 깨짐)
데이터 저장 및 관리
- 데이터 분석을 용이하게 하는 클라우드 컴퓨팅의 잠재적 장점 및 단점
'클라우드 아키텍처'
인프라를 사용하고자 하는 사람이 하드웨어를 구입할 필요 없이 실제 사용하는 리소스를 기반으로 아마존이나 마이크로소프트 같은 회사에서 임대할 수 있는 모델
'클라우드 컴퓨팅'
- 네트워크 기능과 하드웨어를 제공하는 서비스 및 저장장치로서의 인프라 제공하는 플랫폼
- 소프트웨어를 제공하는 서비스로서의 플랫폼(EX-JAVA, Python을 실행할 수있는 운영체제)
장점
- 고성능 컴퓨팅 작업을 수행할 수 있음
- 대규모로 구입하는 것은 매우 비싼데, 사용하려는 시간만큼만 임대 가능하다.
- 그래픽 처리 장치를 기반으로 최적화된 다양한 컴퓨터 사용이 가능하다. -> 많은 병렬 프로세스를 실행, 높은 CPU 또는 대량의 RAM 실행이 가능 -> 병렬 처리에 유용한 예시) 빅데이터 처리를 위해 아마존은 하둡 클러스터를 실행하는데 사용 가능한 서비스 제공
- NoSQL(ex: MongoDB)같은 DB는 수평적 규모로 확장이 가능하므로, 하나 이상의 서버 사용이 가능하다.
- 선행 비용, 유지보수 지용, 에너지 비용이 안든다.
- 거의 모든 데이터 저장 또는 처리가 무제한으로 가능
- 대부분의 작업이 지불하는 비용보다 훨씬 많은 기능을 제공
- 사용량이 증가 할때는 추가 서버를 들이고, 사용량이 감소하는 때에는 추가 서버를 끈다.
단점
- 다른 당사자가 데이터를 보유 가능하므로 지역 데이터 보호법에 따라 데이터 보호할 필요가 있다.
- 기존의 아키텍처보다 더 많은 비용이 들수도 있다. (EX-소프트웨어를 서비스로 사용하는 경우, 실제로 소프트웨어를 소유하지 않아 사용하는 기간동안 비용을 지불해야한다.)
- 내가 설정한 방식으로 특정업체가 사용하게 될 가능성이 존재하여 추후에 다른 플랫폼으로 변경하고 싶은 경우 선택 옵션이 제한 될수 있다.
- EULA의 조항에 따라 서비스 제공 업체가 허용할 수 있는 것에 대한 유연성이 부족할 수도 있다.
- DBMS 와 NoSQL 시스템의 차이점 발견
NoSQL DB의 일부만이 SQL 구문을 이용한다.
by. Brewer's CAP
데이터베이스는 잠재적으로는 3가지를 제공할 수 있지만, 실제로는 각 DB마다 2가지만 제공한다.
CAP : 일관성(Consistent), 가용성(Avaliable), 파티션(Partitioning)

-MongoDB
MongoDB 란, 바이너리 JSON(BISON)이라는 JSON 스타일 형식으로 데이터를 저장하는 데이터베이스
- 기존의 일관성과 가용성의 제약을 받지 않으면서 수평적 확장 기능을 가짐
- 설정 스키마를 지정할 필요 없음
- 자바 스크립트라는 쿼리 언어로 사용
- 널리 사용되는 프로그래밍언어가 모두 사용 가능한 드라이버를 가져서 다양한 플랫폼에서 작동
PyMongo for Python
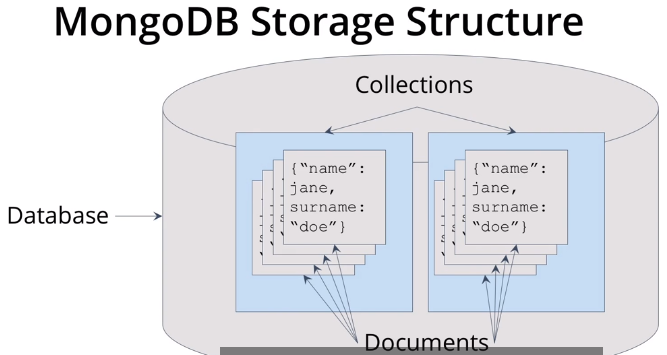
* MongoDB 쿼리
점 표기법 을 이용해 개별 컬렉션에 액세스 가능
모든 사용자 목록 = db.users.find()
쿼리에 조건 추가 = db.users.find({"surname":"Tables"}) : 테이블에서 성을 가진 사람을 컬렉션에서 반환find 쿼find 쿼리의 결과 = 커서(자체적 메소드 존재) = db.users.find().count(): 쿼리의 개수
| 관계형 데이터베이스 | MongoDB |
| 스키마 적용 O - 스키마가 있는 경우 정규화가 시행되어 데이터 비트의 결합을 위한 최적화를 가능하게 한다. |
스키마 적용 X - SQL을 사용하면 스키마가 적용 되므로 미리 설정해야하며, 데이터 모델이 정기적으로 변경된다면 상당한 문제 발생 가능 - 다양한 컬렉션에서 데이터를 가져오려면 여러번 서버를 왕복 이동해야 한다. (일부 데이터 중복은 피할 수 없음) - 유연성있음 |
| 트랜잭션 지원 O - DB에서 발생하는 변경사항과 변경사항을 분리하는 관계형 DB 의 기능 - 일관성 유지에 매우 중요 |
원자성 요소 허용 O, 트랜잭션 지원 X - 변경사항이 발생하지 않음 - 트랜잭션과 유사한 기능을 가지고 있으나, 관계형 데이터베이스보다 훨씬 복잡하다. |
| 수직적 확장 데이터베이스가 상주하는 서버의 처리능력을 향상 |
수평적 확장 - 대신 수평적 확장이 훨씬 수월 =관계형 데이터베이스보다 MongoDB를 사용하는 가장 큰 이유 - " 즉각적 샤딩 지원" :데이터베이스의 다양한 부분을 다양한 서버에 배치 가능하며, 이는 수평적 확장을 가능하게 한다. - 다양한 서버에 데이터베이스를 분산시켜 속도와 가용성을 향상 시킨다. - map-reduce 패러다임을 즉시 지원하는데, 이는 병렬처리가 많은 경우 유용하다. |
'2021 > JOB DA STUDY' 카테고리의 다른 글
| 6주차: 데이터사이언스의 미래 (0) | 2021.05.18 |
|---|---|
| 5주차 강의: 데이터 시각화 (0) | 2021.05.13 |
| 2주차 강의: 데이터 사이언스의 핵심 개념과 기술 (0) | 2021.04.26 |
| 디자인패턴_Composite Pattern of Structural Pattern (0) | 2021.01.20 |
| 디자인패턴_Factory Method Pattern of Creational Pattern (0) | 2021.01.19 |